
Are you using the Wrong GPT Model?
Are you one of the many people using ChatGPT who are making their lives harder by picking the wrong model for the job?


A Candid Look at OpenAI’s Model Families and a Guide to Using the Right AI Model

Are you one of the many people using ChatGPT who are making their lives harder by picking the wrong model for the job?
The menu of models has gotten more complicated, the names aren't super intuitive, and unless you’ve been neck-deep in AI for the past year, you might not even know what kind of model you’re talking to. This can get confusing, fast.
But here’s the thing. OpenAI’s models are not all the same. They're not even trying to be!
There are two main families of models, and they’re optimized for very different tasks. If you’re treating them like interchangeable chatbots, you’re likely wasting time, getting subpar results, or misjudging what these tools are actually good at.
So let’s clear things up. No hype. No jargon. Just a clear, human explanation of what you’re actually using when you click into ChatGPT.
First, the Two Model Families
At the broadest level, OpenAI’s ChatGPT product is powered by two core model types:
- GPT-x models
- “O” series models (short for “Omni,” if you’re curious, though most people just say “the O models”)
Each family has different strengths. Different design goals. Different quirks.
If you’ve ever wondered why your outputs sometimes feel a little too confident, or too vague, or surprisingly insightful in a weirdly Socratic way… well, which model you’re using might explain a lot.
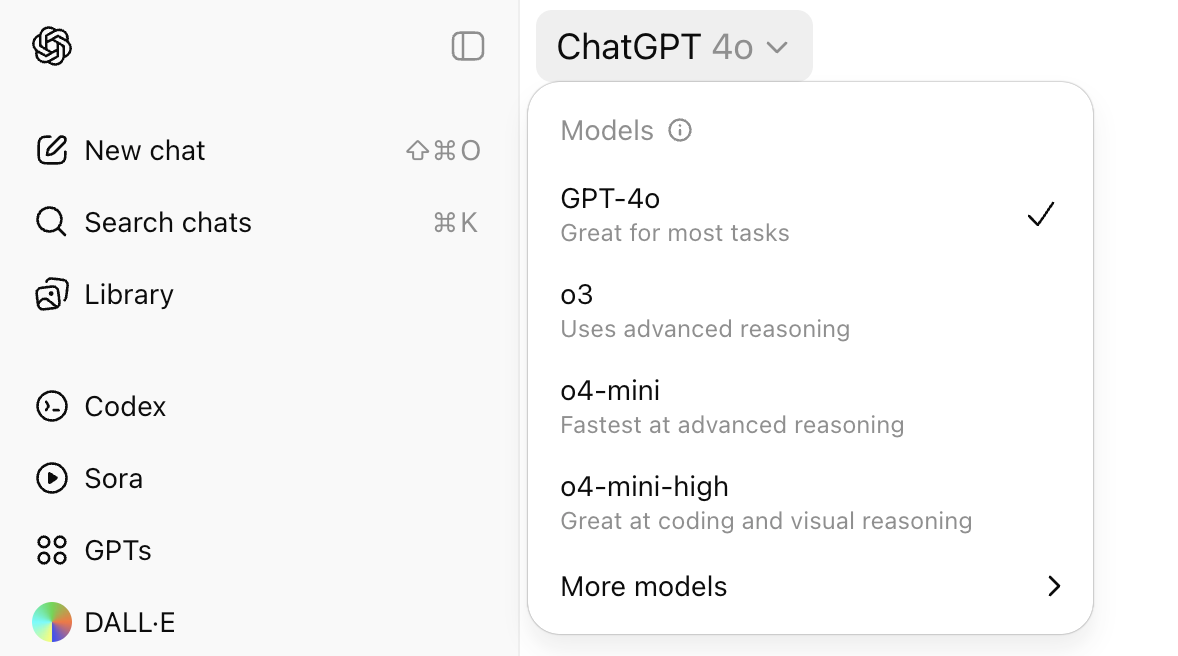
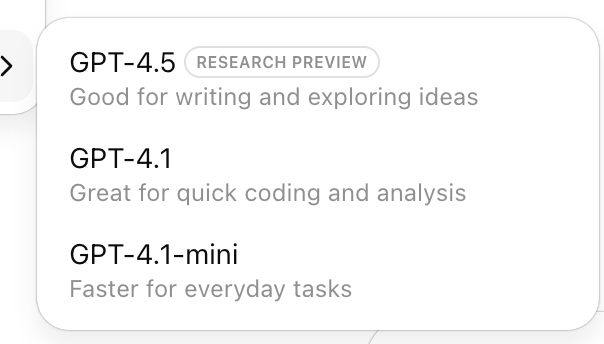
GPT-x: The Generalists
Let’s start with the GPT-x models. These are what most people think of when they think "ChatGPT."
You’ve got things like:
- GPT-4
- GPT-4.5
- GPT-4.1
- GPT-4.1 Mini
- And before that, GPT-3.5 and so on
These are the creative generalists. Good at writing, brainstorming, summarizing, translating, answering basic questions, building out ideas, and generally being helpful across a wide swath of tasks.
They’ve been trained to be fast, flexible, and safe across a broad range of topics. They’re the workhorses. Most casual users and many professionals rely on these daily because they’re consistent and easy to use.
They’ll take your prompt and go, without asking too many questions. They’re efficient, and usually that’s what you want.
But sometimes you need more!
The O Models: For When You Need Depth
Now enter the O series.
These models have names like:
- GPT-0.3
- GPT-0.4-mini
- GPT-0.4-mini-high
At first glance, the names are confusing. The number is smaller, the format looks odd, and you might think it’s a lightweight version or some experimental build.
However, these are actually reasoning-first models. That’s what sets them apart.
The O models are built to think more deliberately. They don’t just jump to an answer. They go through internal steps, argue with themselves a bit, and try to come up with something more grounded. More carefully reasoned.
In practice, that means better logic. Better multi-step answers. And often, better judgment.
Especially when the task is ambiguous, complex, or requires weighing trade-offs.
Let me give a few quick examples.
GPT-x vs. O Models in the Wild
Say you ask:
A GPT-4 model might quickly generate a comprehensive list: some pros, cons, a few best practices, and perhaps even a sample team schedule.
Solid answer. However, you’ll notice it’s somewhat generic. Feels like something you could have scraped from a dozen tech blogs.
Now ask the same question to gpt-0.4-high.
You’re more likely to get an answer that asks questions back. It might say, “It depends on how your team collaborates: is it async-heavy or meeting-driven?” It then walks through various models and their implications. It makes tradeoffs visible.
The tone feels less like autofill and more like you’re talking to someone who thought about it for a beat.
Another example:
GPT-x might hit you with: bias, hallucination, privacy, copyright, and regulatory risk.
The O model might go deeper, question your assumptions, and point out subtle interdependencies: for instance, how transparency and explainability trade off with model performance, or how certain types of bias are harder to detect than others.
Again, it’s not just the what. It’s the how.
So, When Should You Use Each?
Here’s a rough guide:
Use GPT-4 (or 4.5, etc.) when:
- You want speed and fluency
- The task is straightforward or well-defined
- You’re writing, drafting, or ideating
- You’re okay with “good enough” context or surface-level synthesis
Use an O model (like gpt-0.4 or 0.4-high) when:
- The task is reasoning-heavy or involves ambiguity
- You care more about why than what
- You want the model to think through things, not just say them
- You’re making decisions that hinge on trade-offs, logic, or nuance
Of course, there’s overlap. You can do deep thinking with GPT-4, and you can write fluently with an O model. But the defaults matter. If you’ve ever felt like the model “just didn’t get it,” you might’ve picked the wrong one.
A Naming Tangent (Because Yes, It’s Confusing)
Let’s pause and acknowledge the elephant in the room.
These names are a mess.
GPT-4.0 vs. gpt-0.4? Mini vs. high? The O before the number? After?
Even as someone working in tech, I sometimes have to double-check which model is which, because the naming conventions haven’t been fully standardized yet.
The key trick: if the “O” or zero comes before the number, you’re in the reasoning family. If it’s after or not there at all, it’s general purpose.
That’s it. Not elegant, but it works.
Why This Matters More Than You Think
Picking the right model isn’t just about getting a better answer; it's about getting the correct answer. It’s about using the tool for what it’s built to do.
Imagine going to a Michelin-star chef and asking for a grilled cheese. You’ll get one, sure. But it’s not what they’re best at. Flip that, and you might get a beautifully intricate meal from someone who just wanted to toast some bread.
Context matters. Intent matters.
Using the right model can save you hours. It can sharpen your thinking. And if you’re building workflows, writing code, analyzing markets, or designing systems, the difference between surface-level output and solid reasoning is not trivial.
It’s the difference between help and insight.
Not All Intelligence is Created Equal
There’s no shame in defaulting to GPT-4. It’s familiar. It’s friendly. It’ll do most of what you ask without protest.
But if you’re making big decisions, wrestling with trade-offs, or trying to push your own thinking, give the O models a shot. They’re not perfect, but they’re thoughtful in a way that’s easy to miss until you really need them.
And if nothing else, it’s a good reminder that not all intelligence is created equal.
Some models are just better at thinking things through.
So the next time ChatGPT gives you a meh answer, pause before blaming the AI.
You might just be using the wrong one.

Simon Hodgkins,
CMO • President • Editor-in-Chief



